ImageNet Large Scale Visual Recognition Challenge 2013 (ILSVRC2013)
News
- September 2, 2014: A new paper which describes the collection of the ImageNet Large Scale Visual Recognition Challenge dataset, analyzes the results of the past five years of the challenge, and even compares current computer accuracy with human accuracy is now available. Please cite it, along with the original ImageNet paper, when reporting ILSVRC2013 results or using the dataset.
- February 21, 2013: ILSVRC 2013 automated test server is available.
- November 14, 2013: ILSVRC 2013 results are available! Details about the methods coming up at the ICCV 2013 workshop.
- November 11, 2013: Submission site is up. Please submit your results here. (See FAQ for details.)
- September 19, 2013: ICCV 2013 workshop page is up.
- August 15, 2013: The development kit and data are released.
- July 15, 2013: Registration page is up. Please register
- March 18, 2013: We are preparing to run the ImageNet Large Scale Visual Recognition Challenge 2013 (ILSVRC2013). Stay tuned!
- March 18, 2013: The newFine-Grained Challenge 2013 will run concurrently with ILSVRC2013.
- A PASCAL-style detection challenge on fully labeled data for 200 categories of objects,NEW
- An image classification challenge with 1000 categories, and
- An image classification plus object localization challenge with 1000 categories.
This year there is a new object detection task similar in style to PASCAL VOC Challenge. There are 200 basic-level categories for this task which are fully annotated on the test data, i.e. bounding boxes for all categories in the image have been labeled. The categories were carefully chosen considering different factors such as object scale, level of image clutterness, average number of object instance, and several others. Some of the test images will contain none of the 200 categories.
Comparative scale
| PASCAL VOC 2012 | ILSVRC 2013 | ||
| Number of object classes | 20 | 200 | |
| Training | Num images | 5717 | 395909 |
| Num objects | 13609 | 345854 | |
| Validation | Num images | 5823 | 20121 |
| Num objects | 13841 | 55502 | |
| Testing | Num images | 10991 | 40152 |
| Num objects | --- | --- | |
Comparative statistics (on validation set)
| PASCAL VOC 2012 | ILSVRC 2013 | |
| Average image resolution | 469x387 pixels | 482x415 pixels |
| Average object classes per image | 1.521 | 1.534 |
| Average object instances per image | 2.711 | 2.758 |
| Average object scale (bounding box area as fraction of image area) |
0.207 | 0.170* |
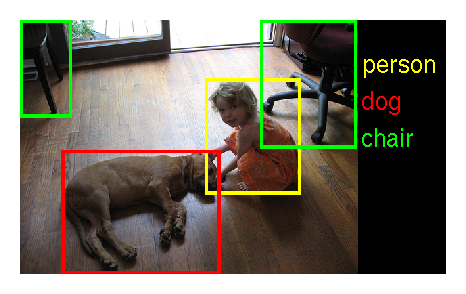
Example ILSVRC2013 images:

|
|

|

|
Note: people detection on ILSVRC2013 may be of particular interest. There are 12125 images for training (9877 of them contain people, for a total of 17728 instances), 20121 images for validation (5756 of them contain people, for a total of 12823 instances) and 40152 images for testing. There is significant variability in pose and appearance, in part due to interaction with a variety of objects. In the validation set, people appear in the same image with 196 of the other labeled object categories.
Dataset 2: Classification and classification with localization
The data for the classification and classification with localization tasks will remain unchanged from ILSVRC 2012 . The validation and test data will consist of 150,000 photographs, collected from flickr and other search engines, hand labeled with the presence or absence of 1000 object categories. The 1000 object categories contain both internal nodes and leaf nodes of ImageNet, but do not overlap with each other. A random subset of 50,000 of the images with labels will be released as validation data included in the development kit along with a list of the 1000 categories. The remaining images will be used for evaluation and will be released without labels at test time.
The training data, the subset of ImageNet containing the 1000 categories and 1.2 million images, will be packaged for easy downloading. The validation and test data for this competition are not contained in the ImageNet training data.
Task 1: Detection NEW
For each image, algorithms will produce a set of annotations $(c_i, b_i, s_i)$ of class labels $c_i$, bounding boxes $b_i$ and confidence scores $s_i$. This set is expected to contain each instance of each of the 200 object categories. Objects which were not annotated will be penalized, as will be duplicate detections (two annotations for the same object instance). The winner of the detection challenge will be the team which achieves first place accuracy on the most object categories.
Task 2: Classification and localization
In this task, given an image an algorithm will produce 5 class labels $c_i, i=1,\dots 5$ in decreasing order of confidence and 5 bounding boxes $b_i, i=1,\dots 5$, one for each class label. The quality of a labeling will be evaluated based on the label that best matches the ground truth label for the image. The idea is to allow an algorithm to identify multiple objects in an image and not be penalized if one of the objects identified was in fact present, but not included in the ground truth.
The ground truth labels for the image are $C_k, k=1,\dots n$ with $n$ class labels. For each ground truth class label $C_k$, the ground truth bounding boxes are $B_{km},m=1\dots M_k$, where $M_k$ is the number of instances of the $k^\text{th}$ object in the current image.
Let $d(c_i,C_k) = 0$ if $c_i = C_k$ and 1 otherwise. Let $f(b_i,B_k) = 0$ if $b_i$ and $B_k$ have more than $50\%$ overlap, and 1 otherwise. The error of the algorithm on an individual image will be computed using two metrics:
- Classification-only: \[ e= \frac{1}{n} \cdot \sum_k \min_i d(c_i,C_k) \]
- Classification-with-localization: \[ e=\frac{1}{n} \cdot \sum_k min_{i} min_{m} max \{d(c_i,C_k), f(b_i,B_{km}) \} \]
Development Kit
- Overview and statistics of the data.
- Meta data for the competition categories.
- Matlab routines for evaluating submissions.
Development kit  (updated Aug 24, 2013)
(updated Aug 24, 2013)
Please be sure to consult the included readme.txt file for competition details. Additionally, the development kit includes
- August 15, 2013: Development kit, data and evaluation software made available.
- November 15, 2013: Submission deadline.
- November 22, 2013: Extended deadline for updating the submitted entries (details in FAQ).
- December 7, 2013: ImageNet Large Scale Visual Recognition Challenge 2013 workshop at ICCV 2013. Challenge participants with the most successful and innovative methods will be invited to present.
- Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, Li Fei-Fei. Imagenet: A Large-Scale Hierarchical Image Database. CVPR 2009.
bibtex
-
Olga Russakovsky*, Jia Deng*, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg and Li Fei-Fei. (* = equal contribution) ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015.
paper |
bibtex |
paper content on arxiv
- Olga Russakovsky ( Stanford University )
- Jia Deng ( Stanford University )
- Jonathan Krause ( Stanford University )
- Alex Berg ( UNC Chapel Hill )
- Fei-Fei Li ( Stanford University )
- Alexei Efros ( CMU )
- Derek Hoiem ( UIUC )
- Jitendra Malik ( UC Berkeley )
- Chuck Rosenberg ( Google )
- Andrew Zisserman ( University of Oxford )

